
在蛋白质组学研究中,科学家需要解决两个核心问题:蛋白质结构预测和蛋白质序列测定。前者在AlphaFold等深度学习模型的推动下取得了革命性突破,几乎将结构预测的难题一举攻克;而后者,尤其是基于质谱技术的蛋白质测序,还缺乏类似的里程碑式进展。为了解决这一问题,我们提出了π-PrimeNovo,这是一种全新的非自回归Transformer模型,专为蛋白质测序设计。它不仅克服了现有方法在精度和速度上的局限性,还在多个生物学应用领域展现出卓越表现。
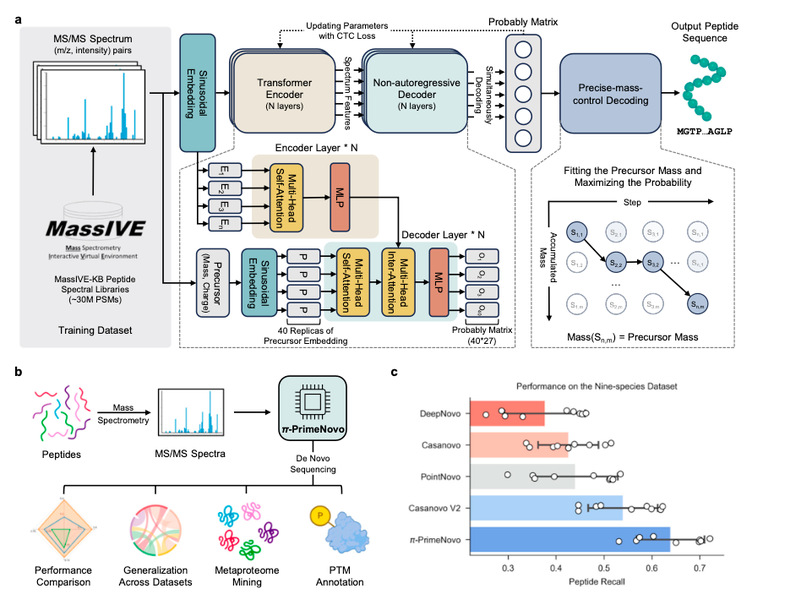
蛋白质测序的重要性:解锁生命密码
蛋白质是生命活动的核心执行者,几乎参与了所有重要的生物过程,包括修复组织、调节代谢、传递信号甚至保护免受疾病侵害。了解蛋白质的功能,首先需要知道它的序列——由氨基酸组成的长链,类似于拼写单词的字母。质谱仪是测定蛋白质序列的主要工具,通过将蛋白质分解成较短的肽段,然后测量这些片段的质量和特性,科学家可以推断出氨基酸的排列顺序。
目前,传统蛋白质测序方法大多依赖数据库搜索,即将测得的质谱数据与已知蛋白质序列进行比对。如果序列不在数据库中,传统方法就无法识别,这限制了它们在未知蛋白质研究中的应用。然而,自然界中蕴藏着无数尚未被发现的蛋白质,它们可能对科学研究和临床应用具有重要意义。为此,深度学习驱动的从头测序技术(De Novo Sequencing)应运而生。
从头测序的现状与挑战
从头测序技术可以直接从质谱数据中推断蛋白质序列,而不依赖数据库。这一技术的出现,极大地拓展了蛋白质组学的研究范围。然而,目前主流的从头测序模型大多基于自回归生成框架,这种方法虽然借鉴了自然语言处理领域的成功,但在蛋白质测序中表现出了一些明显的不足。
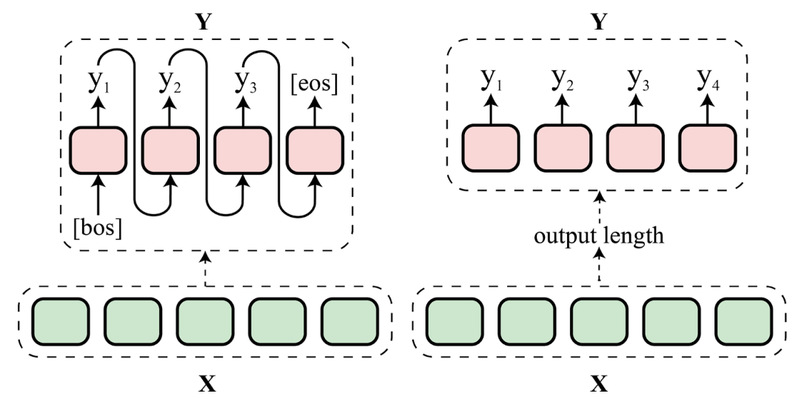
自回归模型的工作原理是逐步生成序列,每一步预测一个氨基酸,并依赖前面的预测结果来推断下一个。这种方法存在三大问题。首先,自回归模型只能利用前文信息,忽略了蛋白质序列中氨基酸间的双向依赖性,导致预测准确性受到限制。其次,自回归模型容易出现错误积累。如果在早期预测中出错,后续预测也会受到连锁影响,最终导致整个序列偏离实际。最后,逐步生成的方式使得自回归模型的解码速度非常慢,对于高通量数据的处理效率较低。
PrimeNovo的突破与创新
PrimeNovo是第一个非自回归的蛋白质测序模型,它彻底颠覆了传统的自回归生成方式,实现了一次性生成整个序列的能力。通过Transformer的自注意力机制,PrimeNovo能够让每个氨基酸在生成过程中同时参考序列中其他位置的信息,从而充分捕捉氨基酸之间的双向依赖关系,显著提高了预测准确性。
为了实现对蛋白质质谱数据的精准控制,PrimeNovo还设计了PMC(Precise Mass Control)模块,结合质谱仪提供的肽段总质量信息,确保生成的序列符合质量约束。与传统模型不同,PMC通过动态规划算法,将解码过程转化为类似“背包问题”的优化问题。在这种设计中,每个氨基酸被看作背包中的物品,其质量和概率共同决定是否被选取。这种方法能够实现质量与序列的全局最优控制,为高精度预测提供了保障。
此外,PrimeNovo还通过CUDA优化底层逻辑,将解码过程完全并行化。相比于传统的自回归模型,其推断速度提高了多达89倍。这种创新设计使得PrimeNovo不仅适用于常规蛋白质测序任务,还能够高效处理海量质谱数据,为大规模研究提供了可能。
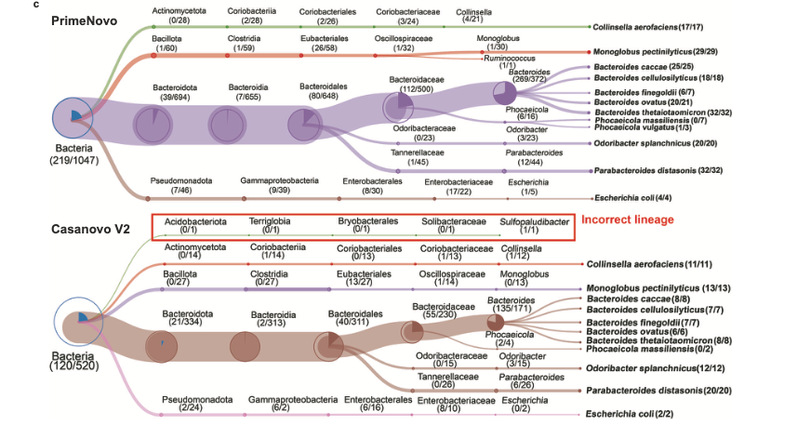
PrimeNovo在宏蛋白质组学中的应用
宏蛋白质组学研究旨在解析复杂环境样本中的所有蛋白质,例如人类肠道微生物群或环境土壤中的蛋白质群落。这些样本中往往包含大量未知的蛋白质序列,传统方法在面对这些复杂样本时常常力不从心。PrimeNovo通过其非自回归架构,能够直接从质谱数据中解码出新的蛋白质序列,无需依赖现有数据库。
在一个包含17种细菌的宏蛋白质组数据集中,PrimeNovo比最优对照模型多鉴定了107%的PSMs(肽段谱图匹配)和124%的肽段数量。这一突破性成果显著提升了分类精度,为研究微生物的生态功能提供了更多线索。例如,通过PrimeNovo,科学家可以识别微生物群落中特定物种的独特肽段,揭示它们在复杂生态系统中的作用。
PrimeNovo在翻译后修饰(PTMs)检测中的表现
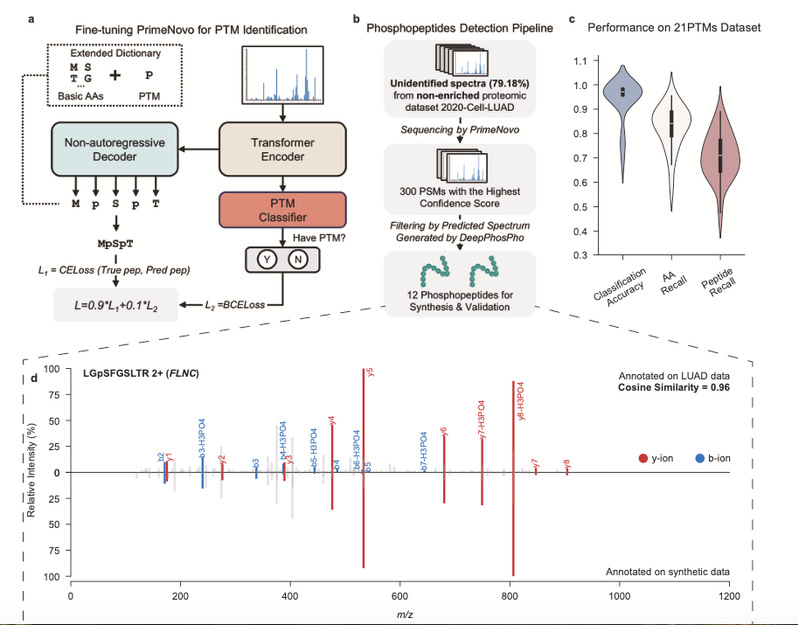
蛋白质的翻译后修饰(如磷酸化、乙酰化等)是调节其功能的重要机制,与癌症、代谢紊乱等多种疾病密切相关。然而,由于翻译后修饰的低丰度和多样性,传统方法在检测这些修饰时往往力不从心。
PrimeNovo通过其精准质量控制和非自回归解码器,在复杂样本中也能捕捉到低丰度的修饰肽段。在肺腺癌患者的数据集中,PrimeNovo成功区分了肿瘤组织和非肿瘤组织中的磷酸化修饰,分类准确率达到98%。更重要的是,它能够精准发现与疾病相关的新型修饰,为深入理解疾病机制和开发新药提供了重要线索。
高可解释性:为深度学习模型注入透明度
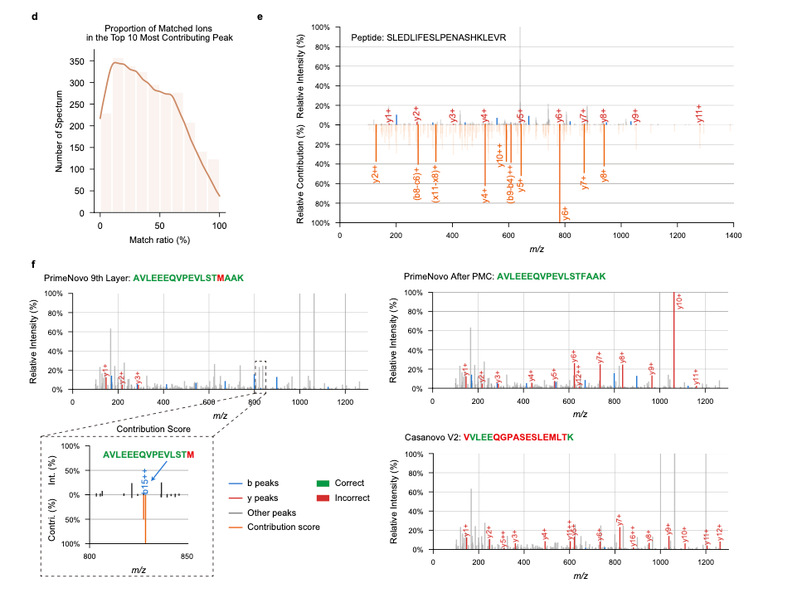
传统的深度学习模型往往被批评为“黑箱”,难以解释其预测结果。而PrimeNovo通过其自注意力机制,让科学家能够追踪哪些质谱峰对最终预测贡献最大。这种高可解释性不仅帮助验证预测结果,还能够为科学家提供新的生物学见解。
例如,在研究某种病原体时,PrimeNovo能够直观展示哪些肽段对预测结果至关重要。科学家可以据此聚焦于关键的质谱数据,进一步开发靶向疫苗或抗体。
总结:为蛋白质组学开辟新天地
PrimeNovo的出现,不仅是技术上的创新,更是科学家探索生命奥秘的重要里程碑。它克服了传统方法的局限,大幅提升了蛋白质测序的效率与准确性。在宏蛋白质组学、翻译后修饰检测以及模型可解释性等领域,PrimeNovo都展现出了革命性潜力。未来,它将继续为基础研究和临床应用提供重要支持,助力科学家更深入地理解生命密码。









