

2026年5月1日,第43届机器学习国际会议ICML2026公布了论文录用结果,复旦大学智能复杂体系基础理论与关键技术实验室林伟教授、朱群喜青年研究员团队共有2篇论文被录用,其中1篇被推荐为Spotlight paper.
作为机器学习领域的国际顶级学术会议,ICML(International Conference on Machine Learning) 被中国计算机学会(CCF)推荐为A类会议,与NeurlPS、ICLR并称为机器学习领域的三大顶会。ICML 2026投稿23,918篇,录用6,352篇,录用率为26.6%,其中,536篇被推荐为“Spotlight papers”,占所有投稿的前2.2%。会议将于7月6日至11日在韩国首尔举行。
Interpretable Functional Koopman Learning with Non-Markovian Closure for Spatiotemporal Systems
基于泛函Koopman学习理论与非马尔可夫闭合的时空系统建模
作者:鲁万丰,马赫,林伟,朱群喜
论文链接:https://drive.google.com/file/d/1B82ATztNcub1b5B_gsvv4X1CJoUP2K8u/view?usp=sharing
接收情况:ICML 2026 Spotlight

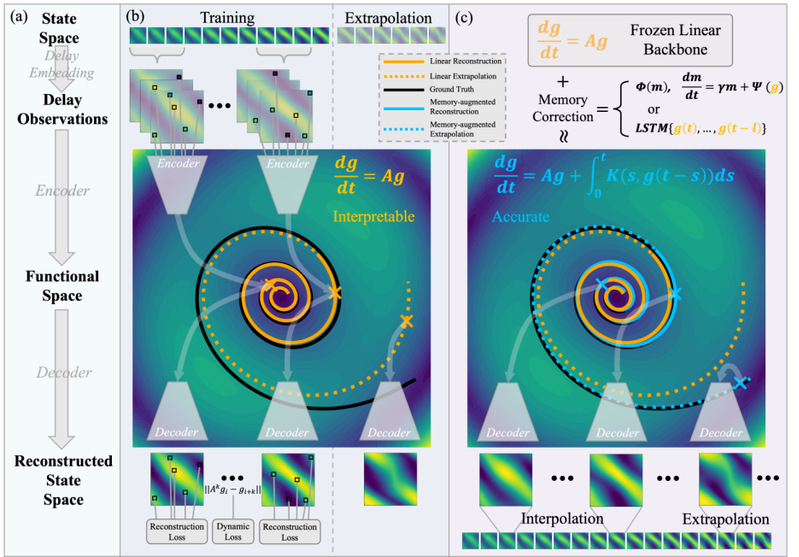
图1: MERLIN 框架概览。第一阶段,基于泛函Koopman理论,稀疏观测的时空场经过函数编码器映射到隐空间,通过训练约束隐空间中的动力学近似线性,函数解码器支持输出任意空间位置的时空动力学状态。第二阶段,学习Mori-Zwanzig理论启发的非马氏闭合,实现更精确的隐空间动力学建模。
时空动力系统广泛存在于气候、湍流和生命系统等领域,其底层规律通常由偏微分方程(PDEs)刻画。然而,长时域预测在实际应用中面临两类核心困难:一方面,高保真数值求解器的计算代价会随积分时间和网格分辨率快速增长;另一方面,真实观测往往稀疏、含噪且不规则采样,难以直接满足许多数据驱动模型对结构化网格或完整场观测的要求。已有神经算子架构(如 FNO)能够学习函数空间映射,但常受到网格结构、截断稳定性与可解释性限制;PINN 则通常依赖已知动力学方程。围绕这一问题,本文提出 MERLIN(Memory-augmented Koopman Evolution with a Resolution-free autoencoder for random partial observations in PDE LearnINg),旨在不显式依赖方程、且只给定随机稀疏观测的条件下,学习一个低维、可解释、可长时稳定外推的时空动力学模型。
MERLIN 的核心思想是把时空场状态从传统离散网格提升到函数空间中的 Koopman 观测泛函(observation functionals),使其在隐空间中尽可能以线性方式演化。针对有限维 Koopman 子空间一般难以实现严格动力学闭合的问题,本文进一步考虑 Mori-Zwanzig 范式,从理论上说明未解析观测量会以时间非局部记忆项的方式反馈到已解析变量的动力学上,从而自然得到“线性 Koopman 骨架 + 非马尔可夫记忆修正”的模型结构。在实现上,MERLIN 采用离散化不变的函数编码器,将任意位置、任意数量的随机稀疏观测映射为固定维的隐变量;再通过分辨率无关的 Fourier型函数解码器,在任意查询点重建完整时空状态场。训练过程分为两阶段:第一阶段学习近似线性的 Koopman 骨架及可重建隐空间表示,第二阶段冻结线性骨架并学习记忆修正,以补偿有限维线性闭合假设的缺失(图1)。
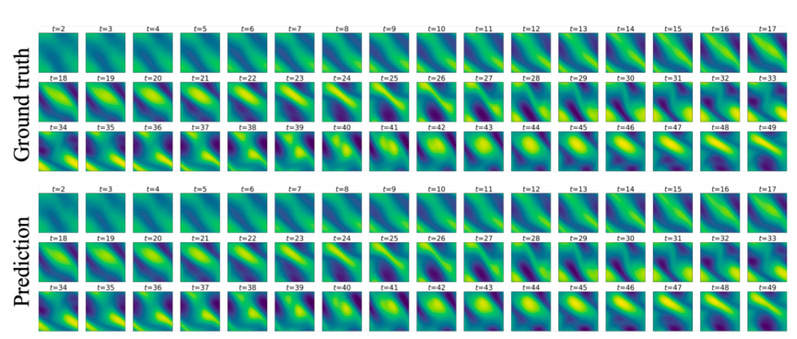
图2: MERLIN在二维不可压缩 Navier-Stokes 方程上的外推表现
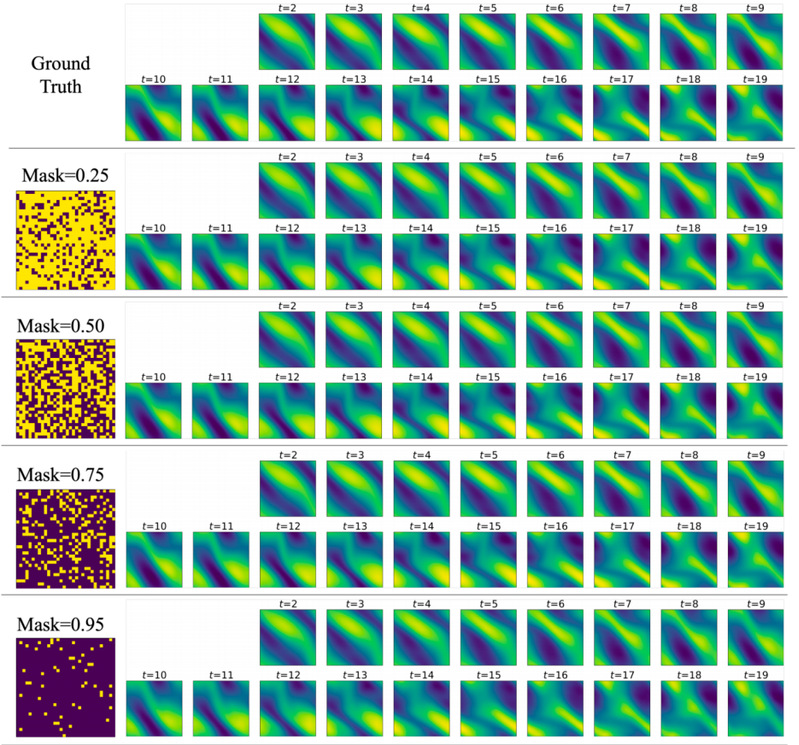
图3: 从稀疏观测中重构、预测完整的时空场演化结果
数值实验部分,本文在二维波方程、二维不可压缩 Navier-Stokes 方程和真实海表温度(SST)等数据上进行训练。结果显示,在合成 PDE 任务中,MERLIN 虽然在训练时域内略逊于具有强 Fourier 归纳偏置的 FNO,但在测试时域的外推中误差累积更小,展现出更好的长时预测稳定性;在真实 SST 任务上,MERLIN 在训练时域和测试时域均显著优于对比基线方法。由于编码器和解码器均面向连续场而非固定网格,模型还能自然处理高比例随机缺失的稀疏观测,并支持不规则点查询、数据补全和超分辨率重建。
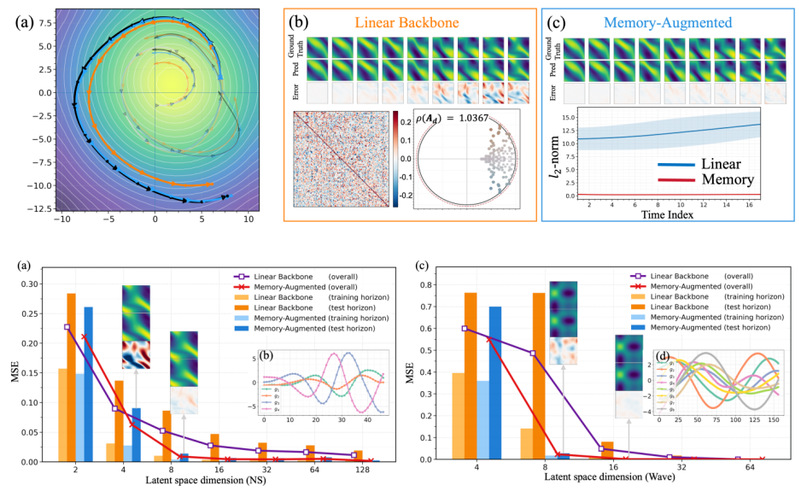
图4: 线性 Koopman 骨架与非马氏记忆修正模型对比,以及降阶建模结果。
除长时域预测性能外,MERLIN 的另一个重要优势是可解释性和降阶建模能力。线性 Koopman 骨架可近似捕捉主导动力学模态,记忆项则以极弱的校正能量将线性轨迹拉回真实隐空间轨迹附近,既提升了预测精度,同时也保留了 Koopman 结构的可解释性。进一步,通过在高维隐空间上加入线性投影头,模型可以得到更低维的降阶动力学;实验表明,Navier-Stokes 方程中少至 8 个泛函观测量即可捕捉大部分动力学演化结构。本文将泛函 Koopman 理论、Mori-Zwanzig 非马尔可夫闭合与离散化无关的神经表示结合起来,为稀疏不规则观测条件下的长时域时空动力学预测和可解释科学机器学习提供了新的建模范式。
该论文已被 ICML 2026 接收为 Spotlight Paper。该论文的共同第一作者是复旦大学数学科学学院2024级博士生鲁万丰和2023级博士生马赫, 通讯作者是复旦大学林伟教授与复旦大学智能复杂体系实验室朱群喜青年研究员。
Hyperparameter Transfer Laws for Non-Recurrent Multi-Path Neural Networks
面向非循环多路径神经网络的超参数迁移定律
作者:张灏松、吴沈曦、卞诗瑞、马行健、张一弛、陈溪、林伟
论文链接:https://drive.google.com/file/d/1lFTOWYz_Y0ji2_x5lEmeJHYlCtwVpBzp/view?usp=sharing

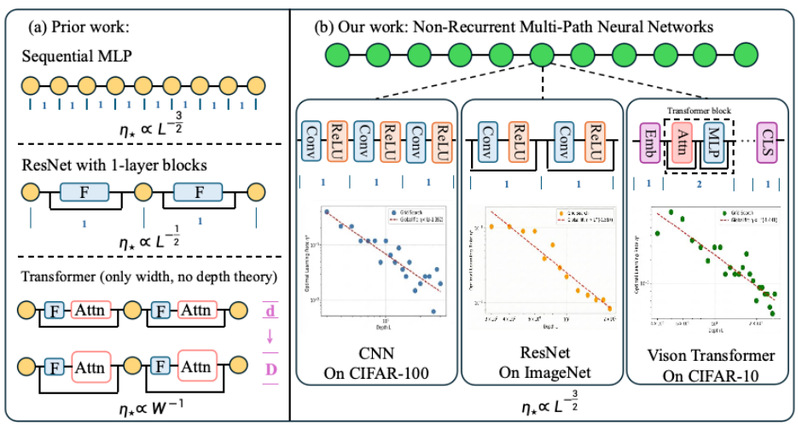
图5: 既有工作与本文关于深度方向学习率缩放规律的结果概览
深度扩展是现代神经网络提升性能的重要方式,但也带来了高昂的超参数调节成本。尤其是学习率,当模型从浅层扩展到深层时,原本在小模型上有效的学习率往往不能直接使用,研究者通常需要在目标深度上重新进行大规模网格搜索。已有最大更新参数化(Maximal Update Parametrization, μP)为“宽度”方向的超参数迁移提供了理论基础,即先在窄模型上调参,再零样本迁移到宽模型;然而,现代网络并不是简单的同质多层感知机,而是广泛采用卷积、残差连接、注意力模块与多路径聚合结构。CNN中的空间共享与边界效应、ResNet中的残差累积、Transformer中的并行分支都会导致不同层的更新统计高度异质,使得传统逐层控制更新幅度的μP原则难以直接刻画“深度”方向的学习率变化规律。
针对上述问题,本文提出了面向现代非循环多路径神经网络的深度超参数迁移理论,将CNN、ResNet和Transformer等架构统一视为带有并行路径与分支聚合的前馈计算图,并引入有效深度单元来刻画不同架构中真正决定深度缩放的路径长度。在此基础上,本文进一步提出算术平均μP(Arithmetic-Mean μP, AM-μP),不再要求每一层的一步表示更新幅度完全相同,而是约束全网络平均的一步pre-activation更新二阶矩保持在常数尺度,从而为异质多路径架构提供统一的最大稳定学习率准则。具体而言,本文的主要贡献包括:(1)有效深度建模:针对CNN、ResNet和Transformer等不同结构,定义与最短输入输出路径和残差聚合一致的有效深度单位,使不同架构能够在同一深度尺度下比较学习率缩放规律。(2)全局更新能量预算:将经典μP从逐层更新约束推广到网络级平均更新约束,在保留“最大但稳定的表示更新”这一核心思想的同时,更自然地适配卷积、残差和多分支结构中的层间异质性。(3)统一深度学习率缩放律:在稳定初始化和最大更新准则下,理论证明CNN、ResNet以及Transformer等非循环多路径网络的最大学习率随有效深度L近似服从η*(L)∝L^(-3/2)的统一幂律关系,并由此得到简单的跨深度迁移规则η(L)=η(L0)(L/L0)^(-3/2),即只需在参考深度L0上调一次学习率,便可直接预测目标深度L上的候选学习率。实验结果表明,该规律在CNN、ResNet和多种Transformer变体上均得到验证,并在CIFAR-10、CIFAR-100和ImageNet等数据集上呈现稳定的log-log线性趋势;不同激活函数、padding方式、归一化和正则化策略主要影响常数项,而不会改变主导的-3/2深度指数。本文将深度扩展中的学习率选择从经验驱动的反复搜索转化为可预测、可迁移的缩放规则,为现代深层网络的低成本训练和可复现调参提供了统一理论与实用指导。
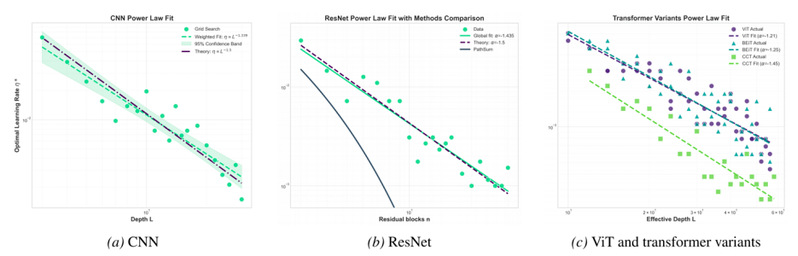
图6:CIFAR-10 上的深度--学习率缩放规律。
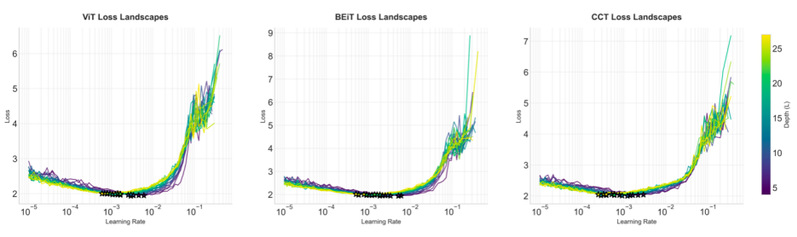
图7:CIFAR-10 上 ViT 变体的损失景观。
该论文的共同第一作者是复旦大学数学科学学院2022级本科生张灏松和复旦大学计算与智能创新学院2022级本科生吴沈曦, 通讯作者是纽约大学Stern商学院2025级博士生张一弛、纽约大学Stern商学院陈溪教授和复旦大学林伟教授。